Étude : Les risques cachés associés à l'IA

Le cabinet de conseil Arthur D. Little publie une analyse des dépendances cachées des entreprises à l'IA : la réalité de son empreinte environnementale, sous-estimée, son futur modèle de prix et la concentration de sa chaîne de valeur, en particulier en amont.
PublicitéL'IA est au coeur de la stratégie de la plupart des organisations. C'est un euphémisme. Elle va de pair avec des choix technologiques, la définition d'une politique de gouvernance ou des démarches d'accompagnement des métiers. L'étude prospective « AI hidden dependancies » (les dépendances cachées de l'IA), publiée le 14 janvier par le Blue Shift Institute (impact des technologies sur les entreprises, la société et les humains) du cabinet Arthur D. Little, révèle d'autres enjeux, voire des risques, moins visibles, associés à ces stratégies.
Le rapport évoque ainsi l'ampleur réelle des impacts environnementaux de l'IA, l'inévitable augmentation à venir de ses prix, mais aussi sa supply chain géographiquement très concentrée. Autant de typologies de risques rarement mis en avant, qui devraient cependant peser dans les choix et stratégies des DSI et de leurs directions générales.
Mesurer l'empreinte d'un LLM de façon globale
Le premier risque est donc environnemental. Pas de surprise en soi. L'impact de l'IA et de ses datacenters sur la consommation de métaux rares, d'énergie ou d'eau, ainsi que ses émissions de GES (gaz à effet de serre) à différentes étapes de sa chaîne de valeur, n'est plus un secret. Pour autant, aucun éditeur d'IA ne publie encore de données détaillées ni vérifiables sur sa consommation de ressources ou ses émissions. Ce que le rapport d'Arthur D. Little précise, ce sont les raisons pour lesquelles la situation est probablement pire qu'elle n'apparaît. Albert Meige, directeur et fondateur du Blue Shift Institute, explique, par exemple, que, contrairement aux dires des acteurs du secteur, l'inférence est de plus en plus consommatrice. En cause, le nombre croissant d'utilisateurs d'IA - selon diverses sources, le seul ChatGPT est passé de 100 millions d'utilisateurs en novembre 2023 à 400 millions en février 2025 et à plus de 800 millions en novembre - et « l'explosion des usages embarqués, c'est-à-dire masqués en quelque sorte, dans le navigateur Internet, voire l'OS »
Un volume exponentiel de requêtes de plus en plus complexes
L'été dernier, Sam Altman, patron et fondateur d'OpenAI, confirmait que ses utilisateurs n'envoyaient rien moins que 2,5 milliards de prompts chaque jour ! Pour cette raison - ajoutée à la complexification des requêtes -, Blue Shift Institute pointe ainsi du doigt le fait que les mesures « par requête » masquent des « effets au niveau système, comme la consommation cumulative d'énergie, mais aussi le renouvellement de matériel ou les effets de rebond liés à une utilisation en continu. » Il rappelle ainsi que, si une seule requête GPT-4 a besoin de moins de 0,3 Wh, son inférence globale engloutit jusqu'à 2700 GWh par an. D'autres modèles consomment davantage pour une seule requête, mais moins globalement. Un constat qui démontre la complexité du calcul de l'empreinte de l'IA, et la présence potentielle de coûts cachés.
PublicitéL'inférence, championne de l'empreinte environnementale
Enfin, ce qui renforce l'idée d'une empreinte de l'IA sous-estimée - davantage même que les impacts de l'agentique, par exemple -, ce sont les usages embarqués. Une forme d'IA masquée. « C'est le cas des navigateurs d'OpenAI ou de Perplexity qui automatisent certaines tâches pour lesquelles l'IA prend la main, complète Albert Meige. Ces usages embarqués vont de pair, qui plus est, avec la réalisation par l'IA de tâches complexes, de plus en plus coûteuses en énergie, et globalement en impact environnemental. »
La combinaison de l'explosion du nombre d'utilisateurs avec la progression de la complexité des requêtes conduit à une croissance exponentielle des besoins en puissance de calcul pour l'inférence. « Même si j'espère que l'on arrivera à un plateau, ou au moins un ralentissement, confie Albert Meige. Mais on s'attend déjà à ce que ces besoins en puissance de calcul et donc la consommation énergétique soient multipliés par cinq d'ici à 2030 ». Le cabinet Arthur D. Little décompose par exemple l'empreinte de GPT 4 en s'appuyant sur des sources diverses, dont l'article de recherche sur le coût environnemental de son inférence (« How hungry is AI? Benchmarking energy, water, and carbon footprint of LLM inference »), piloté par Nidhal Jegham, chercheur en durabilité de l'IA et de la data à l'université de Rhode Island (États-Unis). Un article de recherche qui décompose le cycle de vie des différents LLM et en calcule l'impact. Résultat, si la consommation énergétique sur un an associée aux matériaux nécessaires aux équipements destinés à l'entrainement de l'IA représente entre 2 et 8 GWh, celle de l'assemblage de ces mêmes équipements entre 0,1 et 1 GWh, on grimpe à entre 30 et 42 GWh pour l'entrainement du modèle. Et la consommation de l'inférence se situe, elle, dans un imposant intervalle de 1700 à 2700 GWh sur un an. Les proportions sont du même ordre pour la consommation d'eau et les émissions de GES à chaque étape du cycle de vie.
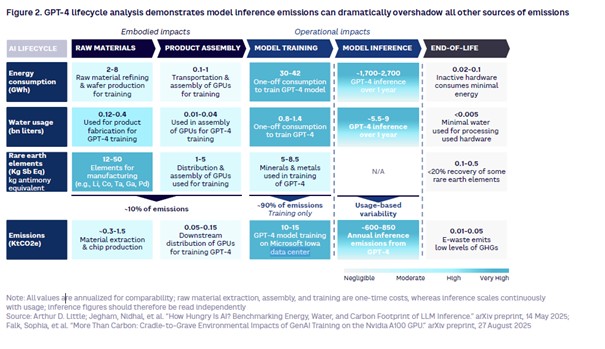
L'empreinte environnementale de chacune des étapes du cycle de vie de GPT-4. (sources diverses compilées par Arthur D. Little)
En matière de consommation énergétique, les datacenters demeurent un sujet central, mais, là encore, les conséquences sont plus complexes qu'elles n'apparaissent. Selon S&P Global Market intelligence 451 research, cité par le rapport Blue Shift Institute, en 2030, la puissance électrique nécessaire aux datacenters en Europe - tous usages confondus - devrait représenter près de deux fois celle de 2024 (36 GW contre 18,87 GW). Mais l'électricité fournie à ces centres de calcul n'est donc pas le seul sujet d'inquiétude. Albert Meige pointe également du doigt les incidences du caractère très local des infrastructures nécessaires à l'IA, et donc des besoins en électricité et en eau, eux aussi très locaux. « Si l'on regarde les projections en matière de besoins énergétiques et de capacités énergétiques à 2030, on devrait disposer en principe d'une capacité suffisante pour les datacenters dédiés à l'IA, explique Albert Meige. En revanche, ces infrastructures provoquent déjà des stress hydriques locaux importants, ainsi qu'un stress sur la grille électrique qui n'a pas du tout été conçue pour cela ».
Des effets délétères sur les grilles énergétiques locales
« Ainsi, on peut rapidement faire sortir de terre un datacenter, poursuit-il, mais il peut se passer plusieurs années avant de pouvoir le raccorder à la grille énergétique, et donc de le rendre opérationnel. En fonction des zones géographiques, cela peut aller jusqu'à 7 ou 8 ans ». Du côté de la consommation d'eau, le directeur de l'institut Blue Shift explique par exemple que l'une des technologies de refroidissement les plus efficaces pour les datacenters, le refroidissement par évaporation, consiste en résumé à transformer en vapeur une eau puisée dans les nappes phréatiques, avant de la rejeter à l'extérieur. « Mais elle n'est donc plus accessible au niveau local ».
Enfin, le rapport aborde également la dépendance des entreprises, mais aussi de certains états, à l'IA et trois grands types de vulnérabilités associées : une vulnérabilité environnementale, encore une fois, mais aussi financière et même géographique, voire géopolitique. « Nous montrons dans un graphe comment le niveau de transparence du reporting environnemental des fournisseurs de solutions sur leurs modèles a progressé jusqu'à 2023 avant de chuter, précise pour commencer Albert Meige. Les entreprises ne peuvent donc pas connaitre précisément leur impact en lien avec leur usage de l'IA. Le risque, c'est que quand la réglementation évoluera de nouveau dans le 'bon' sens, elles soient surprises par leur empreinte véritable et peinent à remettre les choses en ordre. » À partir de 2019, selon le graphe du Blue Shift Institute, entre 3 et 12% des éditeurs d'IA les plus représentatifs ont réalisé des reportings de leurs émissions de GES (gaz à effet de serre), avec des données concernant directement le sujet. Et entre 31 et 62% ont fourni des données indirectes, c'est-à-dire permettant indirectement de calculer cette empreinte, comme le poids du modèle ou la puissance de calcul nécessaire à l'entrainement. Mais en 2023, ils n'étaient plus que 2% à fournir des données directes et 33% des données indirectes.
Réclamer des informations standardisées
Un changement qui, selon les chercheurs consultés par Arthur D. Little, intervient après la bascule de 2022 vers des modèles commerciaux. Pour Albert Meige, cette tendance s'est accentuée avec la politique américaine depuis le début du second mandat de Donald Trump. Le rapport d'Arthur D. Little conclut à la nécessité, pour les organisations, de demander davantage d'informations de la part des fournisseurs, mais surtout d'exiger une information plus standard, pour comparer les modèles. Et ce, malgré le recul de la régulation, aux États-Unis avec la nouvelle administration, mais aussi dans l'Union européenne, avec la directive environnementale omnibus, version allégée de la précédente régulation.
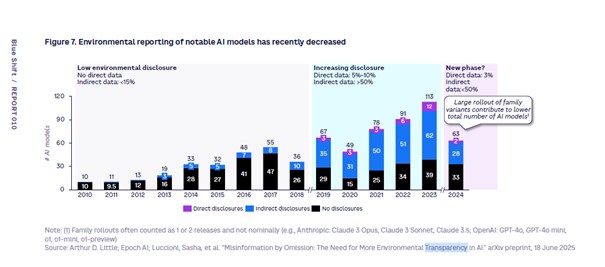
Niveau de diffusion des informations directes et indirectes permettant de calculer l'empreinte des modèles d'IA. (Sources diverses compilées par Arthur D. Little)
Autre effet masqué, l'impact économique. « Personne ne paye aujourd'hui le vrai coût de l'IA, insiste Albert Meige. Il y a aujourd'hui une complète décorrélation entre les investissements en capex, en particulier des fournisseurs de solutions d'IA, et la valeur qu'ils en retirent. Et la base payante est insuffisante aujourd'hui pour rendre les éditeurs rentables. Dans l'avenir, les fournisseurs n'auront pas d'autre choix que d'augmenter leurs prix, que ce soit en dollars, via la publicité ou via des versions premium donnant accès aux modèles les plus récents. » Il s'agit donc pour les entreprises de se préparer à ces changements de modèles, en particulier en anticipant des hausses de prix raisonnables, à négocier. Mais chat échaudé craignant l'eau froide, les récentes explosions des prix chez VMware depuis son rachat par Broadcom, et les hausses de prix et modifications de contrats sans préavis chez quasiment tous les grands éditeurs depuis le raz-de-marée SaaS, auront peut-être a minima sensibilisé les entreprises.
Enfin, 3e enjeu, l'extrême concentration de la chaîne de valeur de l'IA. On connait déjà l'hégémonie américaine sur le cloud et les applications, ou celle que les États-Unis partagent avec la Chine sur la donnée d'entrainement et les applicatifs - les modèles proprement dits. Mais Albert Meige rappelle aussi la concentration de la chaîne amont de l'IA. La lithographie des puces est à 100% entre les mains du Néerlandais ASML et leur design très majoritairement chez l'Américain Nvidia (entre 80 et 95% de parts de marché). Enfin, c'est le Taïwanais TSMC qui fabrique la quasi-totalité des puces. En ce qui concerne ce dernier, la géopolitique s'invite clairement aux côtés des enjeux de concentration économique. Mais il est aussi évident, qu'à l'exception d'ASML, l'Europe n'est pas représentée dans cette chaîne amont. Pour le Blue Shift Institute, c'est un risque que les organisations peuvent parer en exploitant plusieurs modèles et en s'assurant contractuellement de la portabilité des données, mais aussi des logiques d'apprentissage.
Article rédigé par

Emmanuelle Delsol, Journaliste
Suivez l'auteur sur Linked In,
Commentaire
INFORMATION
Vous devez être connecté à votre compte CIO pour poster un commentaire.
Cliquez ici pour vous connecter
Pas encore inscrit ? s'inscrire